La comunicación síncrona, como la basada en HTTP/REST, si bien es común en arquitecturas de microservicios, puede generar acoplamiento temporal entre servicios, lo que dificulta la resiliencia y la escalabilidad. Para mitigar estos desafíos, la comunicación asíncrona con RabbitMQ emerge como una solución fundamental, permitiendo la construcción de sistemas robustos y distribuidos. Sin embargo, en cualquier sistema de mensajería, la aparición de mensajes que no pueden ser procesados y, por ende, no enrutados correctamente, presenta un punto crítico que requiere una gestión cuidadosa.
Este artículo se adentra en el manejo de "mensajes no enrutables" en RabbitMQ, explorando las estrategias de gestión de errores, la importancia de las Dead Letter Queues (DLQ) y cómo implementar un sistema de reintentos para asegurar la fiabilidad en la transmisión de datos entre microservicios.
La Naturaleza de los Mensajes No Enrutables
Un mensaje se considera "no enputable" cuando, por diversas razones, RabbitMQ no puede entregarlo a su destino previsto. Esto puede ocurrir por varias causas, incluyendo:
- Errores en el Consumidor: El servicio que debe procesar el mensaje falla repetidamente al intentar deserializarlo, validarlo o procesar su contenido.
- Configuración Incorrecta de Colas y Exchanges: La lógica de enrutamiento definida en RabbitMQ no coincide con la estructura de los mensajes o la disponibilidad de las colas de destino.
- Ausencia de Consumidores: No hay ningún servicio escuchando en la cola designada para recibir el mensaje.
- Expiración del Mensaje (TTL): El mensaje tiene un tiempo de vida limitado (Time To Live) y expira antes de ser consumido.
- Límites de Cola Alcanzados: Si una cola tiene un límite de tamaño o número de mensajes y este se alcanza, los nuevos mensajes pueden ser rechazados.
Cuando un mensaje no puede ser enrutado, es crucial tener un mecanismo para capturarlo y gestionarlo, en lugar de simplemente descartarlo. Aquí es donde entran en juego las Dead Letter Queues (DLQ).
Dead Letter Queues (DLQ): El Rincón de los Mensajes Problemáticos
Una Dead Letter Queue (DLQ) es una cola especial en RabbitMQ diseñada para recibir mensajes que no han podido ser entregados a su cola de destino original o que han sido rechazados por alguna razón. La configuración de una DLQ implica asociarla a una cola principal a través de una política de "dead-lettering".
Cuando un mensaje es publicado a un exchange y este no puede encontrar una cola enlazada que coincida con la clave de enrutamiento, o cuando un consumidor rechaza un mensaje de una manera que activa la política de dead-lettering (como un nack sin reintento), el mensaje es enviado a la DLQ configurada.
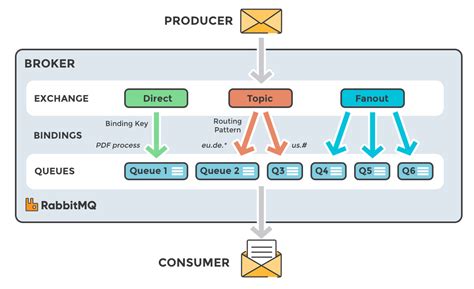
La configuración de la DLQ se realiza típicamente definiendo:
- Un Exchange para la DLQ: Un exchange dedicado a recibir los mensajes "muertos".
- Una Cola de DLQ: La cola donde residirán los mensajes no enrutables.
- Una Clave de Enrutamiento para la DLQ: La clave que el exchange de la DLQ utilizará para enrutar los mensajes a la cola de DLQ.
Posteriormente, la cola de origen se configura con el argumento x-dead-letter-exchange apuntando al exchange de la DLQ y x-dead-letter-routing-key especificando la clave de enrutamiento para la cola de DLQ.
Estrategias de Gestión de Errores y Reintentos
El código proporcionado ilustra una aproximación a la gestión de errores dentro de un consumidor de RabbitMQ. Analicemos las estrategias implementadas y cómo se relacionan con los mensajes no enrutables:
// src/infrastructure/messaging/RabbitMQConsumer.tsexport class RabbitMQConsumer { // ... (otras propiedades y constructor) private async handleMessage(msg: ConsumeMessage | null): Promise<void> { if (!msg || !this.channel) return; const startTime = Date.now(); const eventType = msg.properties.type; try { const event = this.serializer.deserialize<DomainEvent>(msg.content); const handler = this.handlers.get(eventType); if (!handler) { this.logger.warn(`No handler found for event type: ${eventType}`); this.channel.ack(msg); // Acknowledges the message, but it wasn't processed return; } await handler.handle(event); this.channel.ack(msg); // Acknowledges successful processing this.logger.info('Message processed successfully', { eventType, durationMs: Date.now() - startTime }); } catch (error) { await this.handleError(msg, error as Error); } } private async handleError(msg: ConsumeMessage, error: Error): Promise<void> { const retryCount = this.getRetryCount(msg); const maxRetries = this.options.maxRetries ?? 3; if (error instanceof RetryableError && retryCount < maxRetries) { // Será reencolado con delay via dead letter exchange this.channel!.nack(msg, false, false); // Requeue the message } else { // Enviar a dead letter queue permanentemente this.channel!.nack(msg, false, false); // Nack without requeueing, effectively sending to DLQ if configured this.logger.warn('Message sent to dead letter queue', { reason: retryCount >= maxRetries ? 'Max retries reached' : 'Non-retryable error' }); } } private getRetryCount(msg: ConsumeMessage): number { // Assuming retry count is stored in message properties or headers // This is a placeholder and needs actual implementation return parseInt(msg.properties.headers?.['x-retry-count'] || '0', 10); }}1. Manejo de Errores Genéricos y Específicos:
El método handleError es el corazón de la estrategia de resiliencia. Distingue entre errores "reintentables" (RetryableError) y aquellos que no lo son.
Errores Reintentables: Si el error es de tipo
RetryableErrory el número de reintentos aún no ha alcanzado el máximo (maxRetries), el mensaje se marca connack(msg, false, false). En RabbitMQ,nackconrequeue: falseymultiple: falseindica que el mensaje debe ser rechazado y, si la cola tiene configurada una DLQ, será enviado allí. Sirequeuefueratrue, el mensaje volvería a la cola original. La lógica actual parece enviar a DLQ en ambos casos denack, pero la intención es reencolar si es reintentable. Una implementación más precisa para reintentos con delay implicaría añadir un TTL al mensaje antes de enviarlo de vuelta a una cola de reintento, o depender de la funcionalidad de reencolado si el broker lo soporta de forma inteligente.Errores No Reintentables o Límite de Reintentos Alcanzado: Si el error no es reintentable, o si ya se han agotado los reintentos permitidos, el mensaje se marca con
nack(msg, false, false). Esto, asumiendo una configuración adecuada de DLQ en la cola de origen, resulta en el envío del mensaje a la Dead Letter Queue. Se registra una advertencia indicando que el mensaje ha sido enviado a la DLQ.
2. Contador de Reintentos:
La función getRetryCount es un placeholder para obtener el número de veces que un mensaje ha sido reintentado. Una implementación común es almacenar este contador en las propiedades del mensaje o en sus cabeceras. Cada vez que un mensaje es reencolado o enviado a la DLQ por un error reintentable, este contador debe incrementarse. La lógica de handleError utiliza este contador para decidir si aplicar la estrategia de reintento o enviar permanentemente a la DLQ.
3. Acknowledgment (ACK/NACK):
this.channel.ack(msg): Se utiliza cuando el mensaje se procesa con éxito o cuando no hay un manejador para el tipo de evento. En el caso de no haber manejador, el mensaje se considera "procesado" en el sentido de que no se puede hacer nada más con él por parte de este consumidor, por lo que se confirma su recepción.this.channel.nack(msg, false, false): Se utiliza para indicar que el mensaje no ha podido ser procesado. Los parámetrosfalse, falsesignifican que no se rechazan múltiples mensajes y que el mensaje no debe ser reencolado automáticamente en la cola de origen. Si la cola tiene una DLQ configurada, estenacksin reencolado es lo que activa el envío a la DLQ.
Implementación Práctica y Consideraciones Adicionales
La gestión de mensajes no enrutables va más allá de la configuración de DLQs. Requiere una estrategia integral:
Monitoreo de la DLQ
Es fundamental monitorear activamente la DLQ. Una DLQ que crece constantemente indica un problema persistente en la aplicación o en la infraestructura de mensajería. Las herramientas de monitoreo deben alertar cuando el número de mensajes en la DLQ supera un umbral aceptable.
Procesamiento de Mensajes de la DLQ
Una vez que los mensajes llegan a la DLQ, es necesario un proceso para investigarlos y, si es posible, recuperarlos:
- Análisis Manual: Los mensajes en la DLQ pueden ser inspeccionados manualmente para identificar la causa raíz del problema.
- Procesamiento Automatizado: Se puede implementar un consumidor específico para la DLQ que intente procesar los mensajes nuevamente, quizás después de una corrección en el código o una limpieza de datos.
- Reenrutamiento Condicional: En algunos casos, los mensajes de la DLQ pueden ser reenviados a una cola de "reprocesamiento" para un nuevo intento.
Estrategias de Reintento Avanzadas
La estrategia de reintentos puede ser más sofisticada:
- Backoff Exponencial: En lugar de reintentar inmediatamente, esperar un tiempo que aumenta exponencialmente con cada fallo. Esto evita sobrecargar el sistema durante periodos de inestabilidad.
- Mensajes con TTL y Colas de Reintento: Una técnica común es publicar el mensaje a una "cola de reintento" con un TTL específico. Si no se consume antes de que expire, se envía a la DLQ. Si se consume y falla, se publica de nuevo en la cola de reintento con un TTL incrementado.
Serialización y Deserialización
La fiabilidad de la serialización y deserialización es crucial. Si el formato del mensaje cambia o contiene datos corruptos, los consumidores fallarán. Es importante tener esquemas de mensajes bien definidos y mecanismos para manejar versiones de esquemas.
El Rol del API Gateway y la Comunicación Síncrona
Aunque este artículo se centra en la comunicación asíncrona con RabbitMQ, es importante recordar el contexto de las arquitecturas de microservicios. El API Gateway (como Kong o Ocelot) gestiona la comunicación síncrona y puede interactuar con sistemas de mensajería asíncrona. Un API Gateway bien configurado puede, por ejemplo, publicar eventos en RabbitMQ para iniciar procesos asíncronos, o manejar la respuesta de servicios que utilizan colas de mensajes.
La información sobre Ocelot, por ejemplo, destaca su capacidad para reenviar solicitudes HTTP entrantes a servicios de bajada. Si bien esto es comunicación síncrona, la arquitectura subyacente puede apoyarse en RabbitMQ para tareas que requieren desacoplamiento y resiliencia. En escenarios complejos, un API Gateway puede incluso orquestar la publicación de mensajes en colas de RabbitMQ.
RabbitMQ dead-letter management made easy!
Integraciones y Soluciones de Seguridad
La seguridad es un aspecto transversal. Soluciones como las de Qumulo y Varonis, que protegen contra ataques de ransomware y gestionan el acceso a datos, son vitales en cualquier arquitectura. Si bien estas soluciones se centran en la protección de datos y la detección de amenazas, la fiabilidad de la comunicación asíncrona a través de RabbitMQ es un componente que, si falla, puede impedir la aplicación efectiva de estas capas de seguridad. La correcta gestión de mensajes no enrutables asegura que los eventos de seguridad o los comandos de acción puedan ser procesados de manera oportuna.
Conclusión Parcial
La gestión de mensajes no enrutables en RabbitMQ es un pilar fundamental para construir sistemas de microservicios resilientes. Las Dead Letter Queues, combinadas con estrategias de reintento bien definidas y un monitoreo proactivo, permiten manejar fallos de manera elegante, asegurando que la información crítica no se pierda. La implementación de estos mecanismos, como se esboza en el código de RabbitMQConsumer, es esencial para mantener la integridad y la disponibilidad de las aplicaciones distribuidas. La continua evolución de las arquitecturas de microservicios, con herramientas como API Gateways y orquestadores, debe siempre considerar la robustez de la comunicación asíncrona como base para la fiabilidad del sistema.
tags: #mensajes #no #enrutables #rabbitmq