El tiempo de inactividad cuesta a las empresas miles de dólares por minuto, lo que hace que la fiabilidad de las redes sea crucial. En este contexto, la conmutación por error MPLS emerge como una tecnología fundamental para garantizar una conectividad ininterrumpida, redirigiendo automáticamente el tráfico cuando las rutas principales fallan. Este artículo explora en profundidad la configuración, implementación y resolución de problemas de los sistemas de conmutación por error MPLS, proporcionando una guía detallada para alcanzar una alta disponibilidad de red.
Comprendiendo los Fundamentos de la Conmutación por Error MPLS
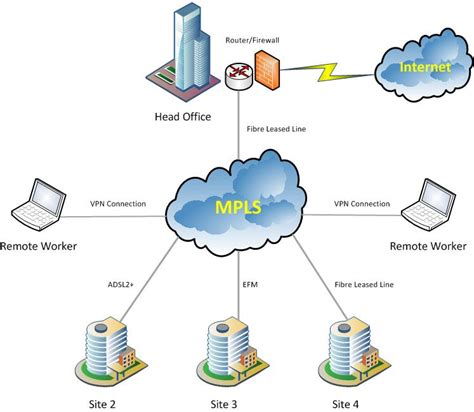
La conmutación por error MPLS se basa en dos tecnologías clave: MPLS (Multiprotocol Label Switching) y la conmutación por error.
MPLS: La Base de la Conectividad Eficiente
MPLS es una tecnología de red que utiliza etiquetas para dirigir el tráfico a lo largo de rutas predefinidas. A diferencia del enrutamiento IP tradicional, que examina la dirección IP de destino en cada salto, MPLS asigna etiquetas cortas a los paquetes en el borde de la red. Estas etiquetas permiten a los routers intermedios (Label Switching Routers - LSRs) tomar decisiones de reenvío de manera mucho más rápida y eficiente. Esto garantiza un rendimiento más rápido y predecible, lo que es esencial para aplicaciones críticas y servicios empresariales. La capacidad de MPLS para crear "túneles" de etiquetas sobre la infraestructura IP subyacente es lo que permite la construcción de redes privadas virtuales (VPNs) y la implementación de servicios de calidad de servicio (QoS) avanzados.
Conmutación por Error: El Mecanismo de Respaldo
La conmutación por error, por otro lado, se refiere a la capacidad de un sistema para cambiar automáticamente a sistemas de respaldo durante interrupciones, minimizando las interrupciones del servicio. Cuando un componente de red principal, como un enlace o un router, falla, el sistema de conmutación por error detecta la falla y redirige el tráfico a través de una ruta o dispositivo alternativo preconfigurado. Este proceso es vital para mantener la continuidad del negocio y la experiencia del usuario.
Alta Disponibilidad: El Objetivo Final
La alta disponibilidad (HA) es el objetivo principal de implementar la conmutación por error MPLS. Se refiere a la capacidad de mantener los sistemas funcionando con un tiempo de inactividad mínimo, generalmente medido en "nueves" de tiempo de actividad (por ejemplo, 99.99% de tiempo de actividad equivale a 52,56 minutos de tiempo de inactividad al año). Lograr una alta disponibilidad requiere una planificación cuidadosa, una implementación robusta y pruebas exhaustivas para garantizar que los mecanismos de respaldo funcionen de manera confiable cuando sea necesario.
Pasos Clave para Configurar la Conmutación por Error MPLS
La configuración de un sistema de conmutación por error MPLS confiable implica varios pasos críticos, desde la infraestructura física hasta las políticas de enrutamiento.
Circuitos Redundantes: La Primera Línea de Defensa
Para garantizar la confiabilidad, es fundamental establecer múltiples rutas de circuito. Esto implica configurar un circuito MPLS primario como la ruta preferida y un circuito secundario como respaldo. Cada circuito debe conectarse a enrutadores de borde del proveedor (PE) separados para minimizar el riesgo de un único punto de fallo.
Además, es crucial que estos circuitos sigan rutas físicas diversas. Si ambos circuitos comparten la misma infraestructura física (por ejemplo, el mismo conducto de fibra), una falla en esa infraestructura afectará a ambos, anulando el propósito de la redundancia.
Cuando se utilizan tipos de conectividad mixtos, como banda ancha o respaldo celular, se deben configurar rutas estáticas en los dispositivos WAN. A estas rutas estáticas se les deben asignar diferentes distancias administrativas, asegurando que la conexión MPLS tenga prioridad sobre otras opciones. Por ejemplo, una ruta estática a través de un enlace de banda ancha podría tener una distancia administrativa más alta que la ruta MPLS principal, lo que significa que solo se utilizará si la ruta MPLS principal no está disponible.
Detección de Conmutación por Error: Identificando la Falla
La detección rápida de fallas en el circuito es esencial para una conmutación por error efectiva. Una técnica común y efectiva es el Monitoreo de ping ICMP. En esta configuración, los enrutadores se programan para hacer ping continuo a destinos críticos a través de cada circuito MPLS. Estos destinos suelen ser direcciones IP de routers de borde del proveedor o servidores internos que se sabe que están siempre activos.
Si el sistema detecta un número específico de fallos de ping consecutivos (normalmente entre 3 y 5), marcará el circuito como no disponible e iniciará los procedimientos de conmutación por error. El número de fallos consecutivos y el intervalo de ping se pueden ajustar para equilibrar la velocidad de detección con la prevención de falsas conmutaciones por error debido a fluctuaciones temporales de la red.
Políticas de Enrutamiento: Dirigiendo el Tráfico Correctamente
Una vez que se detecta una falla, las políticas de enrutamiento determinan cómo se redirige el tráfico. Aquí es donde entran en juego atributos como la preferencia local y la anteposición de ruta AS.
Comunidades BGP para Priorizar Rutas: Las comunidades BGP son atributos opcionales que se pueden adjuntar a las rutas para agruparlas o influir en las decisiones de enrutamiento. En la configuración de conmutación por error MPLS, se utilizan comúnmente para gestionar la preferencia de las rutas. Por ejemplo, se puede asignar una preferencia local de 100 para el circuito principal y 90 para el circuito de respaldo. Dado que un valor de preferencia local más alto indica una ruta más deseable, el router elegirá el circuito principal. Si el circuito principal falla, la preferencia local del circuito de respaldo se vuelve efectivamente la más alta disponible, lo que lleva a la redirección del tráfico.
Para implementar esto, se siguen pasos como:
- Habilitar el formato de la comunidad BGP en el enrutador Customer Edge (CE):
ip bgp-community new-format - Definir una lista de prefijos IP para las redes que requieren conmutación por error:
ip prefix-list PFX-LIST-TO-CTL permit 10.10.10.0/24 - Crear un mapa de ruta que coincida con la lista de prefijos y asigne el valor de comunidad BGP deseado:
route-map SEND-COMM-TO-CTL permit 10 match ip address prefix-list PFX-LIST-TO-CTL set community 209:90route-map SEND-COMM-TO-CTL permit 20El valor de la comunidad209:90establece una preferencia local de 90, haciendo que esta ruta sea menos preferida que el valor predeterminado de 100. La segunda declaración del permiso asegura que otras rutas se anuncien como de costumbre.
Anteposición de Ruta AS (AS-Path Prepending): Otra técnica es la anteposición de ruta AS. En los circuitos de respaldo, se pueden anunciar rutas con una longitud de ruta AS artificialmente extendida. Esto hace que las rutas de respaldo sean menos atractivas en condiciones normales. Si el circuito principal falla, la ruta prefijada se convierte en la siguiente mejor ruta disponible, ya que su longitud de ruta AS ya no es un factor disuasorio.
Pruebas: Validando la Confiabilidad
Una vez configurado el sistema, las pruebas son un paso crucial para garantizar un rendimiento confiable durante las interrupciones. Esto confirma que los circuitos redundantes, los mecanismos de detección y las políticas de enrutamiento funcionan correctamente.
Simulación de Fallos y Monitorización de la Respuesta
La forma más efectiva de probar la conmutación por error de MPLS es simular escenarios de fallo en un entorno controlado. Esto puede implicar desconectar físicamente el circuito primario o utilizar comandos del sistema operativo del enrutador para simular una falla completa del circuito. El objetivo es observar la rapidez con la que la red cambia a la ruta de respaldo.
Para medir el tiempo de detección, se rastrean las respuestas de ping ICMP durante la prueba. Idealmente, el sistema debería detectar fallos en un plazo de 15 a 45 segundos, dependiendo del intervalo de ping y la configuración del umbral de fallo. También se registra el tiempo que tarda el tráfico en redirigirse al circuito de respaldo.
Además, se pueden probar escenarios de degradación parcial, introduciendo pérdida de paquetes o latencia en el circuito principal. Por ejemplo, simular una pérdida de paquetes del 10-15% permite observar la reacción del sistema, ya que muchas configuraciones están diseñadas para conmutar por error cuando la pérdida de paquetes supera el 5% en un período de 30 segundos.
Para un análisis más detallado, se realizan pruebas de convergencia de BGP para observar la rapidez con la que se actualizan las tablas de enrutamiento en la red. Durante una conmutación por error, BGP debería retirar las rutas asociadas con el circuito fallido y anunciar la ruta de respaldo. El comando show ip bgp se utiliza para verificar que los anuncios de ruta se actualicen en un plazo de 30 a 60 segundos. Es importante asegurarse de que los valores de preferencia local se ajusten automáticamente, convirtiendo el circuito de respaldo en la ruta preferida.
Uso de Herramientas de Monitorización de Red
Las herramientas de monitorización de red son esenciales para validar el rendimiento de la conmutación por error.
Monitoreo SNMP (Simple Network Management Protocol): SNMP ofrece información en tiempo real sobre la conmutación por error de MPLS. Se configura el sistema de gestión de red para sondear las estadísticas de la interfaz cada 30 segundos y monitorear métricas como el estado de la interfaz, la pérdida de paquetes y la tasa de errores. Se configuran alertas para notificar si la utilización de la interfaz aumenta bruscamente en el circuito de respaldo, lo que indica un evento de conmutación por error.
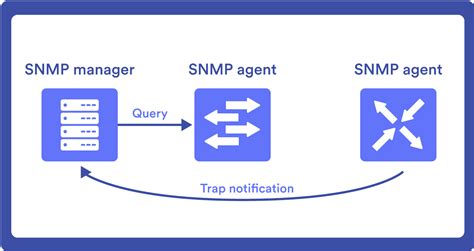
Análisis de Syslog: El análisis de syslog es otra herramienta valiosa para comprender los desencadenantes y la sincronización de la conmutación por error. Se configuran los enrutadores para enviar registros críticos, como eventos de BGP e interfaz, a un servidor syslog centralizado. Se buscan entradas de registro que indiquen que las relaciones de vecinos BGP se interrumpen y se restablecen en circuitos alternativos.
Pruebas de Traceroute: Se ejecutan pruebas de
tracerouteantes, durante y después de las simulaciones de fallos para confirmar que el tráfico sigue la ruta prevista. Por ejemplo, durante una conmutación por error, se debería observar el tráfico redirigido del enrutador PE principal al enrutador PE de respaldo dentro del plazo de detección configurado.Traceroute Explicado | En español
Herramientas de Monitorización del Ancho de Banda: Estas herramientas son esenciales para garantizar que el circuito de respaldo pueda gestionar la carga de tráfico. Si el circuito principal suele transportar 80 Mbps de tráfico, pero el circuito de respaldo solo admite 50 Mbps, podrían experimentarse problemas de rendimiento durante la conmutación por error. Se monitorean los niveles de utilización y se ajusta la planificación de la capacidad según sea necesario.
Registro de Resultados de Pruebas
Una vez finalizadas las pruebas, es fundamental registrar y analizar los resultados. Se documentan los resultados de las pruebas con marcas de fecha y hora precisas (MM/DD/AAAA HH:MM:SS AM/PM). Se incluyen detalles como el tipo de fallo simulado, la hora de detección y la duración del impacto.
Se comienza por crear una línea base de rendimiento que capture el comportamiento normal de la red antes de iniciar las pruebas. Se registra la latencia promedio, la pérdida de paquetes y el rendimiento de los circuitos principal y de respaldo durante las operaciones normales. Esta línea base servirá como punto de referencia para identificar cualquier cambio en el rendimiento durante la conmutación por error.
Se registran también los problemas de configuración detectados durante las pruebas. Por ejemplo, se anotan los comandos específicos del enrutador que no funcionaron como se esperaba y las medidas correctivas implementadas. Si se ajustaron los intervalos de ping, los temporizadores BGP o los retrasos en los anuncios de ruta, también se documentan esos cambios.
Es importante rastrear las métricas de impacto empresarial durante las pruebas de conmutación por error, como los tiempos de respuesta de las aplicaciones, las quejas de los usuarios y los porcentajes de disponibilidad del servicio. Si, por ejemplo, el sistema VoIP experimenta una mala calidad de llamada durante más de dos minutos durante una conmutación por error, se registra este problema para su posterior investigación y optimización.
Finalmente, se establece un calendario de pruebas regular para garantizar la confiabilidad continua. Muchas organizaciones realizan pruebas de conmutación por error mensual o trimestralmente, a menudo durante los períodos de mantenimiento programado, para minimizar las interrupciones. Es recomendable realizar pruebas en distintos momentos del día para comprender cómo las diferentes cargas de tráfico afectan el rendimiento de la conmutación por error. Mantener registros detallados permite realizar un seguimiento de las mejoras a lo largo del tiempo, como tasas de detección más rápidas y menos interrupciones del servicio.
Solución de Problemas Comunes de Conmutación por Error MPLS
Incluso con la mejor preparación, los sistemas de conmutación por error MPLS a veces pueden presentar problemas que interrumpen el funcionamiento normal durante las interrupciones de la red. Reconocer estos problemas y saber cómo abordarlos puede ayudar a garantizar que su red mantenga una alta disponibilidad confiable.
Errores Comunes de Configuración
Atributos BGP no coincidentes: Un error frecuente implica atributos BGP no coincidentes entre los circuitos principal y de respaldo. Por ejemplo, si el circuito principal anuncia rutas con una preferencia local de 200, mientras que el circuito de respaldo utiliza el valor predeterminado de 100, el sistema siempre favorecerá la ruta principal, incluso si su rendimiento es bajo. Para solucionar esto, se debe confirmar que ambos circuitos compartan atributos BGP consistentes. Utilice el comando
show ip bgppara comparar los anuncios de ruta en los enrutadores PE principal y de respaldo y ajuste los valores de Preferencia Local según sea necesario, generalmente a 150 para los circuitos principales y a 100 para los de respaldo.Listas de prefijos incorrectas: Configuraciones incorrectas de la lista de prefijos pueden bloquear los anuncios de ruta. Las listas de prefijos demasiado restrictivas podrían pasar por alto subredes necesarias o rutas de host
/32añadidas posteriormente. Es crucial revisar y validar las listas de prefijos utilizadas en las políticas de enrutamiento para asegurar que incluyan todas las rutas necesarias.Desajustes del temporizador: Los temporizadores de mantenimiento y espera de BGP, así como los temporizadores de los mecanismos de detección de fallos (como los intervalos de ping ICMP), deben estar alineados. Tiempos de espera demasiado cortos pueden provocar falsas conmutaciones por error, mientras que tiempos de espera demasiado largos retrasan la detección de fallos reales. Es importante ajustar estos temporizadores de manera que se logre un equilibrio entre la detección rápida y la estabilidad.
Brechas de capacidad: Un problema crítico surge cuando la capacidad del circuito de respaldo no se adapta a las cargas de tráfico del circuito principal. Si el circuito principal experimenta una falla, el tráfico se redirige al circuito de respaldo, que puede no tener suficiente ancho de banda. Esto puede resultar en congestión, degradación del rendimiento e incluso interrupciones del servicio. Es fundamental dimensionar adecuadamente el circuito de respaldo para manejar al menos una parte significativa, si no la totalidad, del tráfico del circuito principal.
Prerrequisitos y Requisitos de Red para la Conmutación por Error MPLS
Antes de embarcarse en la configuración de la conmutación por error MPLS, es fundamental confirmar que su infraestructura de red esté preparada para soportar alta disponibilidad y procesos de conmutación por error fluidos. Estos pasos fundamentales son clave para construir un sistema de conmutación por error MPLS confiable.
Requisitos de Hardware y Software
Comience con enrutadores de nivel empresarial certificados para MPLS y diseñados para alta disponibilidad. Asegúrese de que el hardware incluya al menos dos interfaces WAN para admitir la redundancia MPLS. Los dispositivos deben ser capaces de gestionar el tráfico MPLS eficientemente sin sacrificar el rendimiento ni la estabilidad. La memoria RAM, la capacidad de procesamiento y las tablas de enrutamiento disponibles son factores importantes a considerar.
Configuración de Red y Requisitos del ISP
Para una confiabilidad óptima, asegúrese de que sus circuitos principal y de respaldo sigan diversos caminos físicos. Esto puede implicar trabajar con diferentes proveedores de servicios o solicitar rutas que utilicen infraestructuras físicas distintas. Además, complemente la redundancia MPLS con una combinación de enlaces WAN, como conexiones de banda ancha, celulares o satelitales. Este enfoque multicapa minimiza el riesgo de problemas de conectividad causados por interrupciones en todo el operador.
Colabore estrechamente con su proveedor de servicios de internet (ISP) para confirmar que la configuración de su red sea compatible con los protocolos de conmutación por error. Una sólida colaboración con su ISP garantiza que sus mecanismos de conmutación por error funcionen sin problemas, lo que refuerza la resiliencia general de su red. Asegúrese de que el ISP pueda proporcionar la infraestructura necesaria para rutas diversas y que sus equipos de borde estén configurados para admitir las necesidades de su red.
Requisitos de Energía y Ambientales
Una alimentación estable y un entorno controlado son tan cruciales como la redundancia de la red. Conecte todos los enrutadores, conmutadores y cortafuegos a sistemas de alimentación ininterrumpida (SAI) para protegerse contra cortes de energía. Utilice fuentes de alimentación redundantes para eliminar puntos únicos de fallo y combine sistemas UPS con generadores de emergencia para cortes prolongados.
Para sistemas críticos para MPLS, mantenga sistemas de refrigeración redundantes para evitar el sobrecalentamiento, especialmente en centros de datos. En zonas propensas a desastres naturales, considere diversificar geográficamente su infraestructura de red para una capa adicional de protección. Por ejemplo, soluciones de alojamiento global pueden mantener los servicios críticos funcionando incluso durante interrupciones locales. Una configuración energética y ambiental confiable es tan importante como los circuitos MPLS redundantes cuando se trata de garantizar una alta disponibilidad y una conectividad ininterrumpida.
Diseño y Configuraciones Empresariales de WAN Dual MPLS + Internet
La implementación de una WAN dual que combine MPLS con Internet es una estrategia común para lograr una alta disponibilidad y flexibilidad.
MPLS con Conmutación por Error de Internet
En este escenario, el circuito MPLS principal proporciona el rendimiento y la predictibilidad necesarios para las aplicaciones críticas. El circuito de Internet actúa como un respaldo de conmutación por error. Cuando el circuito MPLS falla, el tráfico se redirige a través del circuito de Internet. Esto requiere una configuración cuidadosa de las políticas de enrutamiento para garantizar que el tráfico se dirija de manera óptima en ambas condiciones (circuito principal operativo y circuito principal fallido).
La configuración de conmutación por error de Internet para MPLS puede implicar el uso de protocolos como BGP para anunciar rutas a través de ambos enlaces y el uso de atributos BGP (como la preferencia local o la métrica) para priorizar el enlace MPLS. El monitoreo de la conectividad del enlace MPLS, a menudo mediante pings a destinos específicos o supervisión de la ruta BGP, activará la conmutación por error al enlace de Internet.
La principal consideración aquí es la calidad del servicio (QoS) a través de Internet, que es inherentemente menos predecible que MPLS. Por lo tanto, este tipo de conmutación por error es más adecuado para aplicaciones que pueden tolerar una mayor latencia y variabilidad, o para cargas de tráfico menos críticas.
Comandos Clave para la Verificación y Diagnóstico de Errores en Redes MPLS
En el fascinante mundo de las redes de datos, la habilidad para diagnosticar y solucionar problemas es crucial. En el contexto de la certificación CCNA de Cisco, es imperativo que los profesionales de redes comprendan a fondo cómo utilizar los comandos de troubleshooting en los routers. Este artículo se enfoca en algunos comandos esenciales que permiten identificar y resolver problemas comunes en las redes MPLS y sus sistemas de conmutación por error.
Comandos Fundamentales para la Verificación de Rutas y Conectividad
show ip route: Este comando es fundamental para visualizar la tabla de enrutamiento de un router. Permite verificar si las rutas esperadas, incluyendo las aprendidas a través de MPLS o las rutas de respaldo, están presentes y configuradas correctamente. Se puede filtrar por protocolo o por prefijo de red para un análisis más detallado.show ip bgp: Para redes que utilizan BGP para el enrutamiento inter-AS o para la distribución de rutas VPNv4 en entornos MPLS, este comando es indispensable. Muestra la tabla de vecinos BGP, las rutas anunciadas y recibidas, y los atributos asociados a cada ruta, como la preferencia local, la métrica y la longitud de la ruta AS. Es crucial para diagnosticar problemas de adyacencia BGP y de selección de ruta.show mpls forwarding-table: Este comando es específico para entornos MPLS y muestra la tabla de reenvío de etiquetas (LFIB). Permite verificar las etiquetas asignadas a los prefijos y las salidas asociadas, asegurando que el switching basado en etiquetas esté funcionando como se espera.show ip cef: Muestra la tabla de Conmutación Rápida de Paquetes (CEF), que es la base del reenvío de paquetes de alto rendimiento en los routers Cisco. Es importante para verificar que el reenvío de paquetes se esté realizando eficientemente y que las rutas MPLS estén correctamente integradas en la tabla CEF.ping: Este comando te permite verificar la conectividad con otro dispositivo en la red enviando paquetes ICMP Echo Request. Es útil para probar la alcanzabilidad de los destinos de monitoreo de ping, los routers PE y otros puntos clave en la ruta de conmutación por error.Router# ping 8.8.8.8Type escape sequence to abort.Sending 5, 100-byte ICMP Echoes to 8.8.8.8, timeout is 2 seconds:!!!!!Success rate is 100 percent (5/5), round-trip min/avg/max = 16/16/16 mstraceroute(otracerten Windows): Utiliza el comandotraceroutepara visualizar la ruta que toma el tráfico desde el router hasta la dirección IP especificada, mostrando los saltos intermedios. Esto es invaluable para identificar dónde se interrumpe la conectividad durante una conmutación por error o para verificar la ruta activa.Router# traceroute 8.8.8.8Type escape sequence to abort.Tracing the route to 8.8.8.8VRF info: (not specified) 1 <IP_del_primer_salto> 16 msec 16 msec 16 msec 2 <IP_del_segundo_salto> 20 msec 20 msec 20 msec ... 10 8.8.8.8 40 msec 40 msec 40 msec
Comandos para la Verificación de Configuraciones Específicas de Conmutación por Error
show ip interface brief: Proporciona un resumen rápido del estado de las interfaces, incluyendo si están activas (up/up) o caídas (down/down). Esencial para verificar el estado físico y lógico de los enlaces MPLS y de respaldo.show running-config: Permite ver la configuración activa del router. Es fundamental para revisar la configuración de las políticas de enrutamiento, las listas de prefijos, los mapas de ruta, las comunidades BGP y los temporizadores.show ip prefix-list: Muestra las listas de prefijos configuradas, permitiendo verificar su contenido y asegurarse de que coincidan con las rutas esperadas.show route-map: Detalla la configuración de los mapas de ruta, mostrando cómo se aplican las políticas de coincidencia y establecimiento de atributos, como las comunidades BGP.show ip bgp community-list: Si se utilizan listas de comunidades BGP, este comando permite verificar su contenido y cómo agrupan las comunidades.debug ip icmp: Habilitar la depuración de ICMP puede ser útil para observar los pings que se envían y reciben, y para diagnosticar por qué los mecanismos de detección de fallos podrían no estar funcionando. Sin embargo, debe usarse con precaución en entornos de producción debido a su impacto en el rendimiento.
Dominar estos comandos de troubleshooting no solo es esencial para la operación y el mantenimiento de redes MPLS con conmutación por error, sino también para convertirse en un profesional de redes altamente competente. La capacidad de identificar y resolver problemas rápidamente es crucial en entornos de red dinámicos. Al integrar estos conocimientos en tu repertorio, estarás mejor preparado para enfrentar los desafíos del mundo real en el apasionante campo de las redes de datos.